
TL;DR:
- Infrastructure orchestration coordinates multiple automated tasks into dependency-aware workflows, enhancing system reliability and governance. It spans layers such as IaC, configuration management, container orchestration, and workflow automation, integrating various tools like Terraform, Ansible, Kubernetes, and Prefect. Adopting orchestration improves consistency, error reduction, compliance, multi-cloud support, and recovery, but requires disciplined workflow design and focus on failure management.
Many engineers treat infrastructure orchestration as a fancy word for automation. That misunderstanding creates real operational problems. Infrastructure orchestration is something distinct: the coordination of multiple automated tasks into dependency-aware workflows that manage sequencing, retries, state, and governance across your entire infrastructure stack. Automation does the work. Orchestration decides the order, handles failures, and keeps the system coherent. Understanding that difference is where operational maturity begins, and this guide walks through every layer in depth.

Key Takeaways
| Point | Details |
|---|---|
| Orchestration vs. automation | Orchestration coordinates many automated tasks in sequence, managing dependencies and failure recovery. |
| Four foundational layers | IaC, configuration management, container orchestration, and workflow automation combine to deliver end-to-end infrastructure control. |
| Tooling is an ecosystem | No single tool handles everything; Terraform, Ansible, Kubernetes, and workflow platforms interoperate by design. |
| Policy as code is non-negotiable | Embedding compliance rules directly into orchestration workflows prevents non-compliant resources from ever being created. |
| Rollback is a first-class path | Treat recovery and teardown as primary workflows, not afterthoughts, to avoid orphaned resources and broken dependencies. |
What infrastructure orchestration actually means
Running this on your own AWS setup? IT-Magic is an AWS Advanced Tier Partner — we audit, fix, or fully manage it for you.
Get a free consultationInfrastructure orchestration coordinates many automated tasks into cohesive workflows, managing dependencies and sequencing to deliver reliable operations that no individual script can achieve on its own. Think of it as the difference between a musician practicing scales alone and an orchestra performing a symphony. Each instrument (each automation) does its job. Orchestration determines when each plays, what happens if one misses a cue, and how the whole performance recovers from a mistake.
The concept spans four distinct layers that build on each other.
- Infrastructure as Code (IaC): Declarative definitions of resources, networks, and policies written in code and stored in version control. Terraform and AWS CloudFormation sit here. If you want a deeper look at how IaC fits the broader picture, the IT-Magic guide to IaC is worth reading.
- Configuration management: Tools like Ansible and Puppet apply desired state to provisioned resources, installing dependencies, configuring services, and enforcing settings at scale.
- Container orchestration: Kubernetes manages containerized workloads, scheduling, scaling, health checking, and rolling back deployments across clusters.
- Workflow automation: Platforms like Prefect and Dagster coordinate multi-step pipelines that span multiple tools, tracking state across the full execution graph.
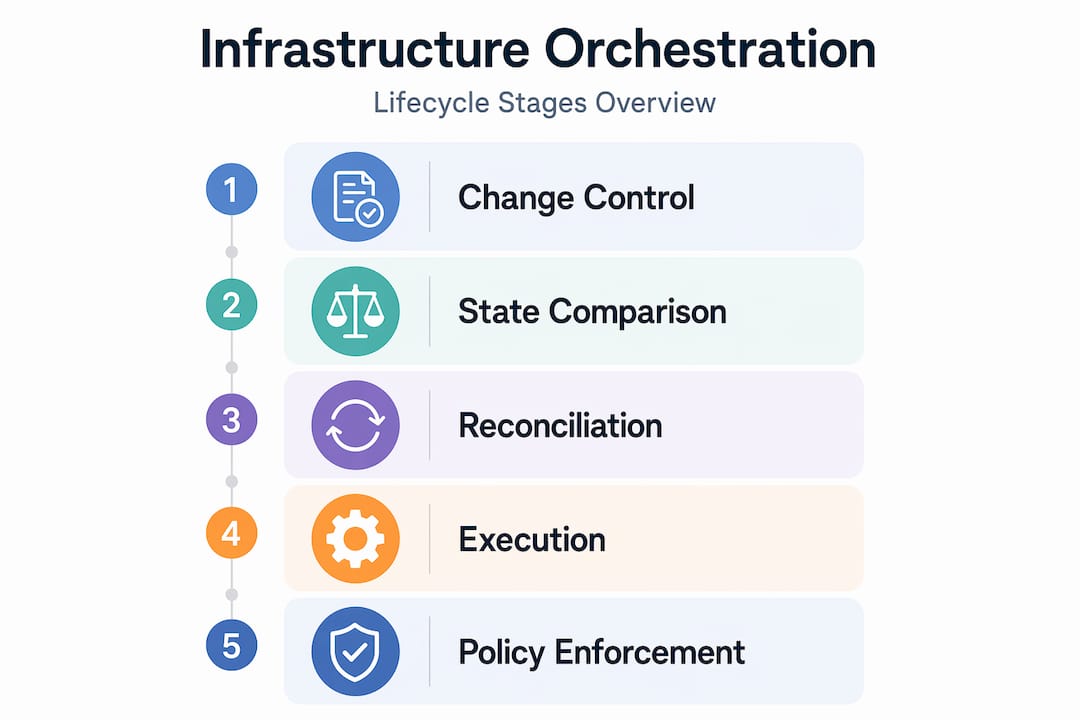
Orchestration in cloud computing typically follows four lifecycle stages: change control, state comparison, reconciliation, and workflow orchestration across cloud and infrastructure layers. Each stage feeds the next. You define the desired state, compare it to reality, reconcile the delta, and track the entire operation as a managed workflow with audit history.
Policy as code deserves special attention here. Pulumi Policies allow teams to write rules that are applied during provisioning to prevent non-compliant resource creation before it happens. This is a fundamentally different posture than scanning for violations after deployment. Governance becomes a pre-execution gate, not a cleanup task.
Pro Tip: Separate your declarative resource definitions (what you want) from your execution logic (how to get there). Mixing them creates brittle workflows that are hard to test, audit, and reuse across environments.
Infrastructure orchestration tools and how they interoperate
No single platform handles the entire orchestration stack. Real-world environments use a layered ecosystem where tools hand off to one another across the infrastructure lifecycle.
| Tool | Category | Primary role in orchestration |
|---|---|---|
| Terraform | IaC provisioning | Declares and provisions cloud resources with dependency graphing |
| AWS CloudFormation | IaC provisioning | Native AWS stack provisioning with built-in rollback |
| Ansible | Configuration management | Configures provisioned resources using agentless playbooks |
| Puppet | Configuration management | Enforces desired state continuously on long-lived infrastructure |
| Kubernetes | Container orchestration | Schedules, scales, and heals containerized workloads |
| Prefect | Workflow automation | Coordinates multi-step data and infrastructure pipelines |
| Dagster | Workflow automation | Asset-centric pipeline orchestration with rich observability |
IBM and Domo list these tools as representative of how integrated orchestration systems are assembled in practice. The key insight is that the integration points between tools matter as much as the tools themselves. Terraform provisions a cluster, Ansible configures its nodes, Kubernetes manages the workloads running on it, and Prefect triggers the whole sequence as part of a deployment pipeline.
Kubernetes is worth singling out here. Kubernetes supports continuous reconciliation, progressive rollouts, health monitoring, and automatic rollback to maintain desired state. These features make it the clearest example of what orchestration actually does in practice: it does not just deploy your containers, it watches them, repairs drift, and rolls back failed updates without human intervention. For teams running containerized workloads on AWS, exploring real-world Kubernetes orchestration scenarios can clarify how these mechanisms work at production scale.
The orchestration pattern across all of these tools follows the same logic. Each tool maintains a model of desired state, compares it to current state, and takes corrective action. When you chain those tools together with workflow automation, you get a system that manages the full lifecycle of your infrastructure with minimal manual intervention.
Benefits of infrastructure orchestration at scale
The benefits of infrastructure orchestration extend well beyond what individual automation scripts deliver. Here is what changes when you operate with a mature orchestration layer in place.
-
Consistency across environments. Every deployment follows the same workflow graph. Dev, staging, and production environments are provisioned identically because the same orchestration definition drives all three. Drift becomes detectable and correctable rather than accumulating silently.
-
Dramatic error reduction. Orchestration coordinates complex dependent tasks with embedded policies and multi-tool integration, replacing fragile hand-off scripts where failures are frequently missed. When a dependency fails, the workflow stops, raises an alert, and waits for resolution rather than proceeding into a broken state.
-
Faster deployments with built-in compliance. Policy checks and security validations run inside the workflow, not as manual pre-deployment reviews. This removes bottlenecks without reducing rigor. Teams deploying to regulated environments (PCI DSS, SOC 2) gain speed and auditability simultaneously.
-
Multi-cloud and hybrid support. Dependency-aware orchestration across clouds handles multi-step processes and ensures compliance and error recovery across providers. A workflow can provision resources in AWS, configure them via Ansible, and register them in an external CMDB as a single tracked operation.
-
Resilience through rollback. Rollback and teardown treated as first-class workflow paths avoid resource leaks and broken dependencies. This is not a nice-to-have. Partial failures in unorchestrated environments routinely leave orphaned resources, incorrect configurations, and inconsistent states that take hours to diagnose.
Operational teams that move from ad-hoc automation to structured orchestration consistently report that the largest gains come not from speed but from predictability. When a deployment fails, the failure is clean, recoverable, and fully logged. That changes how your team responds to incidents.
Best practices for infrastructure orchestration
Getting orchestration right requires discipline in a few specific areas where teams most commonly fall short.
- Modularize your workflows. Large monolithic workflow definitions become unmaintainable fast. Break orchestration into composable modules: one for network provisioning, one for compute, one for application deployment. This makes testing, reuse, and troubleshooting far simpler.
- Enforce policy at decision points. Policy as code should integrate at workflow decision points to prevent non-compliant changes before deployment, not just scan for them afterward. Gates placed early in a workflow are cheaper to act on than violations caught in production.
- Treat failure paths as primary workflows. Partial failures must be safely recoverable to maintain infrastructure integrity. Design your rollback, recovery, and teardown workflows with the same care you give to the happy path.
- Embed observability from the start. Every orchestration run should produce structured logs, emit metrics, and record a full audit trail. Without this, debugging complex multi-tool workflows becomes guesswork.
- Adopt incrementally. Trying to orchestrate your entire infrastructure at once is a reliable way to create a new category of complexity. Start with one well-understood workflow, prove the pattern, then expand.
Pro Tip: When integrating a new tool into your orchestration ecosystem, define the interface contract (inputs, outputs, failure signals) before writing a single line of workflow code. Tools that are poorly integrated at the boundaries cause more incidents than tools that are poorly configured internally.
Common pitfalls worth calling out explicitly: over-engineering the workflow layer before the underlying automation is stable, skipping state management for long-running workflows, and treating orchestration tooling as infrastructure you do not need to test. All three are prevalent and all three are avoidable with deliberate planning.
My take on orchestration after years in the field
I’ve spent years implementing orchestration across AWS environments for startups, fintech platforms, and enterprise clients. The pattern I see repeatedly is this: teams invest heavily in automation (Terraform, Ansible, CI/CD pipelines) and then hit a wall where their automation becomes a source of incidents rather than a cure for them. That wall is exactly where orchestration becomes necessary.
What I’ve learned is that orchestration is primarily a governance and coordination problem, not a tooling problem. Most teams already have the right tools. What they lack is a coherent model of how those tools should hand off to each other, what state each step maintains, and who is responsible when a workflow fails mid-execution.
The hardest lesson I’ve had to teach clients is that rollback is not optional. I’ve seen production environments left in partially deployed states for hours because nobody designed a recovery path. Effective orchestration workflows treat rollback and teardown as fundamental paths to avoid orphaned resources. That is not theoretical advice. It is the difference between a 15-minute recovery and a 3-hour incident.
My honest view on the industry trend: too many vendors are marketing orchestration platforms as turnkey solutions when the real work is cultural and architectural. No tool installs orchestration maturity. Teams have to build it deliberately, workflow by workflow, with rigorous attention to failure modes and state management.
— Oleksandr
How IT-Magic helps you build orchestration that works

Building a mature orchestration layer on AWS requires expertise across IaC, Kubernetes, configuration management, and workflow automation simultaneously. IT-Magic has delivered 700+ infrastructure projects since 2010, and orchestration is at the center of how we design AWS environments for clients in fintech, SaaS, and enterprise.
Our AWS infrastructure support services cover the full orchestration stack: Terraform-based provisioning, policy as code integration, automated compliance workflows, and multi-environment deployment pipelines. For teams running containerized workloads, our Kubernetes support services provide hands-on implementation of orchestration patterns across EKS and ECS, including rollback automation and health-check-driven deployments. If cost visibility is part of your orchestration goals, we also offer AWS cost optimization to track spend across orchestrated workflows. Reach out to discuss where your current automation ends and where orchestration should begin.
FAQ
What is the difference between orchestration and automation?
Automation executes a single task. Orchestration coordinates many automated tasks in a dependency-aware sequence, managing timing, retries, state, and failure recovery across an entire workflow.
What tools are used for infrastructure orchestration?
Common infrastructure orchestration tools include Terraform and CloudFormation for IaC provisioning, Ansible and Puppet for configuration management, Kubernetes for container orchestration, and Prefect or Dagster for workflow coordination. Most production environments use several of these together.
What are the main benefits of infrastructure orchestration?
The main benefits of infrastructure orchestration include consistent, repeatable deployments, automated compliance enforcement, error reduction through dependency management, and built-in rollback capabilities that keep infrastructure in a known good state after failures.
How does orchestration work in a multi-cloud environment?
Cloud orchestration unifies APIs across providers into dependency-aware workflows that handle multi-step processes, state tracking, and error recovery regardless of which cloud the resources live in.
Why is policy as code important in orchestration?
Policy as code embeds compliance rules directly into the orchestration workflow, blocking non-compliant resource creation before it reaches production rather than catching violations in post-deployment audits.
Recommended
- What is infrastructure as code: A guide for IT leaders
- Kubernetes orchestration explained: ensure scalability and control
- Cloud infrastructure monitoring: Boost performance and cut costs
- Cloud Architecture Planning Guide for IT Leaders
Alexander founded IT-Magic, an AWS Advanced Tier Services Partner delivering DevOps, cloud architecture, and managed services since 2010. He holds:
- AWS Certified Solutions Architect – Professional
- AWS Certified DevOps Engineer – Professional
- AWS Certified Security – Specialty
- AWS Certified Advanced Networking – Specialty
Talk to a certified AWS team trusted by INTERTOP, Foxtrot, Pandora, and J.Hilburn.
Get a free consultation

